In a nutshell:
- Data analytics is expensive to perform on a large scale,
- It yields value, for example in the form of predictive models that provide actionable knowledge to decision makers,
- However, such value is liable to decay with time, as the premises (data, algorithms, other assumptions) become obsolete.
With these observations, we address the following question:
Given a finite set of resources available to perform analytics tasks (including a money budget to pay for cloud resources) and a set of analytical tasks that generated value in the past with known cost and outcomes, how do we select candidates for re-computation, in a way that maximises the expected return on the resources?
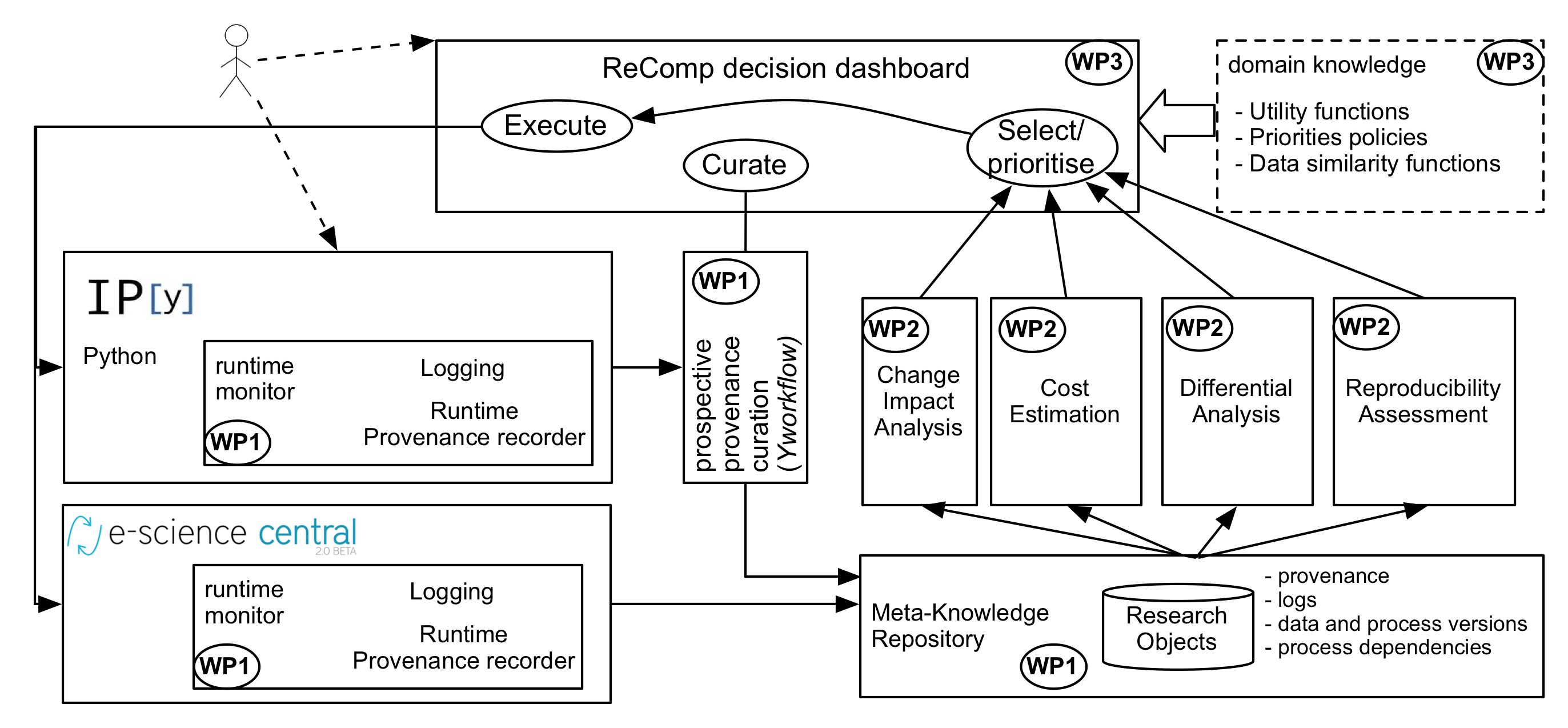
The ReComp project sets out to establish a rich metadata management infrastructure and metadata analytics on top, to enable decision makers to answer these questions.
We are going to validate our architecture and metadata analytics algorithms on two very different case studies:
- genetic diagnostics through NGS data processing, and
- Newcastle’s Urban Observatory: predictive models from smart city data obtained from multiple, diverse sensors, specifically to study the Urban Heat Island effect in large cities.
Who? When?
- ReComp is a 3-year project starting in Jan. 2016.
- Coordinated at Newcastle University School of Computing. PI: Dr. Paolo Missier, CO-I: Prof. Paul Watson.
- In collaboration with: School of Civil Engineering, Newcastle University (Phil James), and University of Cambridge, Dept. of Clinical Neuroscience (Prof. Chinnery).
- External partners: DataONE (US), University of Manchester, UK.
- Funding: EPSRC under the “Making Sense from Data” call.
Project Summary (the longer story)
As the cost of allocating computing resources to data-intensive tasks continues to decrease, large-scale data analytics becomes ever more affordable, continuously providing new insights from vast amounts of data. Increasingly, predictive models that encode knowledge from data are used to drive decisions in a broad range of areas, from science to public policy, to marketing and business strategy. The process of learning such actionable knowledge relies upon information assets, including the data itself, the know-how that is encoded in the analytical processes and algorithms, as well as any additional background and prior knowledge. Because these assets continuously change and evolve, models may become obsolete over time, leading to poor decisions in the future, unless they are periodically updated.
Focus of the project
This project is concerned with the need and opportunities for selective recomputation of resource-intensive analytical workloads. The decision on how to respond to changes in these information assets requires striking a balance between the estimated cost of recomputing the model, and the expected benefits of doing so. In some cases, for instance when using predictive models to diagnose a patient’s genetic disease, new medical knowledge may invalidate a large number of past cases. On the other hand, such changes in knowledge may be marginal or even irrelevant for some of the cases. It is therefore important to be able, firstly, to determine which past results may potentially benefit from recomputation, secondly, to determine whether it is technically possible to reproduce an old computation, and thirdly, when this is the case, to assess the costs and relative benefits associated with the recomputation.
The project investigates the hypothesis that, based on these determinations, and given a budget for allocating computing resources, it should be possible to accurately identify and prioritise analytical tasks that should be considered for recomputation.
Technical approach
Our approach considers three types of meta-knowledge that are associated with analytics tasks, namely:
- Knowledge of the history of past results, that is, the provenance metadata that describes which assets were used in the computation, and how;
- Knowledge of the technical reproducibility of the tasks; and
- Cost/benefit estimation models.
Element (1) is required to determine which prior outcomes may potentially benefit from changes in information assets, while reproducibility analysis (2) is required to determine whether an old analytical task is still functional and can actually be performed again, possibly with new components and on newer input data.
A general framework
As the first two of these elements are independent of the data domain, we aim to develop a general framework that can then be instantiated with domain-specific models, namely for cost/benefit analysis, to provide decision support for prioritising and then carrying out resource-intensive recomputations over a broad range of analytics application domains.
Both (1) and (2) entail technical challenges, as systematically collecting the provenance of complex analytical tasks, and ensuring their reproducibility, requires instrumentation of the data processing environments. We plan to experiment with workflows, a form of high level programming and middleware technology, to address both these problems.
Validation of the approach
To show the flexibility and generality of our framework, we will test and validate it on two, very different case studies where decision making is driven by analytical knowledge, namely in genetic diagnostics, and policy making for Smart Cities.